Cách chuẩn hóa dữ liệu bằng scikit-learn trong Python
05/10/2023 01:20
Trong bài viết này, bạn sẽ thử một số cách khác nhau để chuẩn hóa dữ liệu trong Python bằng scikit-learn, còn được gọi là sklearn.
Trong bài viết này, bạn sẽ thử một số cách khác nhau để chuẩn hóa dữ liệu trong Python bằng scikit-learn, còn được gọi là sklearn. Khi bạn chuẩn hóa dữ liệu, bạn thay đổi tỷ lệ của dữ liệu. Dữ liệu thường được điều chỉnh lại tỷ lệ để nằm trong khoảng từ 0 đến 1 vì thuật toán học máy có xu hướng hoạt động tốt hơn hoặc hội tụ nhanh hơn khi các tính năng khác nhau ở quy mô nhỏ hơn. Trước khi đào tạo các mô hình machine learning trên dữ liệu, thông thường là chuẩn hóa dữ liệu trước để có thể nhận được kết quả tốt hơn, nhanh hơn. Chuẩn hóa cũng làm cho quá trình đào tạo ít nhạy cảm hơn với quy mô của các tính năng, dẫn đến hệ số tốt hơn sau khi đào tạo.
Quá trình làm cho các tính năng trở nên phù hợp hơn cho việc đào tạo bằng cách thay đổi tỷ lệ được gọi là chia tỷ lệ tính năng .
Hướng dẫn này đã được thử nghiệm bằng Python phiên bản 3.9.13 và scikit-learn phiên bản 1.0.2.
Sử dụng chức năng scikit-learn preprocessing.normalize()để chuẩn hóa dữ liệu
Bạn có thể sử dụng hàm scikit-learn preprocessing.normalize()để chuẩn hóa tập dữ liệu dạng mảng.
Hàm normalize()chia tỷ lệ các vectơ riêng lẻ thành một chuẩn đơn vị sao cho vectơ có độ dài bằng 1. Chuẩn mặc định cho normalize()là L2, còn được gọi là chuẩn Euclide. Công thức định mức L2 là căn bậc hai của tổng bình phương của mỗi giá trị. Mặc dù việc sử dụng normalize()hàm sẽ tạo ra các giá trị từ 0 đến 1, nhưng nó không giống như việc chia tỷ lệ các giá trị nằm trong khoảng từ 0 đến 1.
Chuẩn hóa một mảng bằng normalize()hàm
Bạn có thể chuẩn hóa mảng NumPy một chiều bằng normalize()hàm.
Nhập sklearn.preprocessingmô-đun:
Nhập NumPy và tạo một mảng:
Sử dụng normalize()hàm trên mảng để chuẩn hóa dữ liệu dọc theo một hàng, trong trường hợp này là mảng một chiều:
Chạy mã ví dụ hoàn chỉnh để minh họa cách chuẩn hóa mảng NumPy bằng hàm normalize():
Đầu ra là:
[[0.11785113 0.1767767 0.29462783 0.35355339 0.41247896 0.23570226
0.47140452 0.41247896 0.35355339]]
Kết quả đầu ra cho thấy tất cả các giá trị đều nằm trong khoảng từ 0 đến 1. Nếu bạn bình phương từng giá trị ở đầu ra rồi cộng chúng lại với nhau thì kết quả là 1 hoặc rất gần với 1.
Chuẩn hóa các cột từ DataFrame bằng normalize()hàm
Trong DataFrame của gấu trúc, các đối tượng là cột và hàng là mẫu. Bạn có thể chuyển đổi cột DataFrame thành mảng NumPy rồi chuẩn hóa dữ liệu trong mảng.
Các ví dụ trong phần này và các phần sau đây sử dụng bộ dữ liệu Nhà ở California .
Phần đầu tiên của mã ví dụ nhập mô-đun, tải tập dữ liệu, tạo DataFrame và in mô tả của tập dữ liệu:
Lưu ý rằng as_frametham số được đặt thành Trueđể tạo california_housingđối tượng dưới dạng DataFrame của gấu trúc.
Đầu ra bao gồm đoạn trích sau từ mô tả tập dữ liệu mà bạn có thể sử dụng để chọn một tính năng cần chuẩn hóa:
.. _california_housing_dataset:
California Housing dataset
--------------------------
**Data Set Characteristics:**
:Number of Instances: 20640
:Number of Attributes: 8 numeric, predictive attributes and the target
:Attribute Information:
- MedInc median income in block group
- HouseAge median house age in block group
- AveRooms average number of rooms per household
- AveBedrms average number of bedrooms per household
- Population block group population
- AveOccup average number of household members
- Latitude block group latitude
- Longitude block group longitude
...
Tiếp theo, chuyển đổi một cột (đối tượng địa lý) thành một mảng và in nó. Ví dụ này sử dụng HouseAgecột:
Cuối cùng, sử dụng normalize()hàm để chuẩn hóa dữ liệu và in mảng kết quả:
Chạy ví dụ hoàn chỉnh để minh họa cách chuẩn hóa một tính năng bằng normalize()hàm:
Đầu ra là:
HouseAge array: [41. 21. 52. ... 17. 18. 16.]
Normalized HouseAge array: [[0.00912272 0.00467261 0.01157028 ... 0.00378259 0.0040051 0.00356009]]
Kết quả đầu ra cho thấy normalize()hàm đã thay đổi mảng giá trị tuổi nhà trung bình sao cho căn bậc hai của tổng bình phương của các giá trị bằng một. Nói cách khác, các giá trị được chia tỷ lệ theo độ dài đơn vị bằng định mức L2.
Chuẩn hóa tập dữ liệu theo hàng hoặc theo cột bằng normalize()hàm
Khi bạn chuẩn hóa tập dữ liệu mà không chuyển đổi các tính năng hoặc cột thành mảng để xử lý, dữ liệu sẽ được chuẩn hóa theo hàng. Trục mặc định của normalize()hàm là 1, có nghĩa là mỗi mẫu hoặc hàng được chuẩn hóa.
Ví dụ sau đây minh họa việc chuẩn hóa tập dữ liệu Nhà ở California bằng trục mặc định:
Đầu ra là:
MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
0 0.023848 0.117447 0.020007 ... 0.007321 0.108510 -0.350136
1 0.003452 0.008734 0.002594 ... 0.000877 0.015745 -0.050829
2 0.014092 0.100971 0.016093 ... 0.005441 0.073495 -0.237359
3 0.009816 0.090449 0.010119 ... 0.004432 0.065837 -0.212643
4 0.006612 0.089394 0.010799 ... 0.003750 0.065069 -0.210162
... ... ... ... ... ... ... ...
20635 0.001825 0.029242 0.005902 ... 0.002995 0.046179 -0.141637
20636 0.006753 0.047539 0.016147 ... 0.008247 0.104295 -0.320121
20637 0.001675 0.016746 0.005128 ... 0.002291 0.038840 -0.119405
20638 0.002483 0.023932 0.007086 ... 0.002823 0.052424 -0.161300
20639 0.001715 0.011486 0.003772 ... 0.001879 0.028264 -0.087038
[20640 rows x 8 columns]
Đầu ra cho thấy các giá trị được chuẩn hóa dọc theo các hàng sao cho mỗi mẫu được chuẩn hóa thay vì từng tính năng.
Tuy nhiên, bạn có thể chuẩn hóa theo tính năng bằng cách chỉ định trục.
Ví dụ sau đây minh họa việc chuẩn hóa tập dữ liệu Nhà ở California bằng cách sử dụng axis=0chuẩn hóa theo tính năng:
Đầu ra là:
MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
0 0.013440 0.009123 0.008148 ... 0.001642 0.007386 -0.007114
1 0.013401 0.004673 0.007278 ... 0.001356 0.007383 -0.007114
2 0.011716 0.011570 0.009670 ... 0.001801 0.007381 -0.007115
3 0.009110 0.011570 0.006787 ... 0.001638 0.007381 -0.007116
4 0.006209 0.011570 0.007329 ... 0.001402 0.007381 -0.007116
... ... ... ... ... ... ... ...
20635 0.002519 0.005563 0.005886 ... 0.001646 0.007698 -0.007048
20636 0.004128 0.004005 0.007133 ... 0.002007 0.007700 -0.007055
20637 0.002744 0.003783 0.006073 ... 0.001495 0.007689 -0.007056
20638 0.003014 0.004005 0.006218 ... 0.001365 0.007689 -0.007061
20639 0.003856 0.003560 0.006131 ... 0.001682 0.007677 -0.007057
[20640 rows x 8 columns]
Khi kiểm tra kết quả đầu ra, bạn sẽ nhận thấy rằng kết quả của HouseAgecột khớp với kết quả đầu ra bạn nhận được khi chuyển đổi HouseAgecột thành một mảng và chuẩn hóa nó trong ví dụ trước.
Sử dụng chức năng scikit-learn preprocessing.MinMaxScaler()để chuẩn hóa dữ liệu
Bạn có thể sử dụng chức năng scikit-learn preprocessing.MinMaxScaler()để chuẩn hóa từng tính năng bằng cách chia tỷ lệ dữ liệu thành một phạm vi.
Hàm MinMaxScaler()chia tỷ lệ cho từng tính năng riêng lẻ sao cho các giá trị có giá trị tối thiểu và tối đa nhất định, với giá trị mặc định là 0 và 1.
Công thức để chia tỷ lệ các giá trị đặc trưng từ 0 đến 1 là:
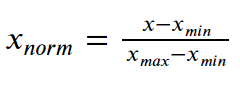
Trừ giá trị tối thiểu từ mỗi mục nhập rồi chia kết quả cho phạm vi, trong đó phạm vi là chênh lệch giữa giá trị tối đa và giá trị tối thiểu.
Ví dụ sau đây minh họa cách sử dụng MinMaxScaler()hàm để chuẩn hóa tập dữ liệu Nhà ở California:
Đầu ra là:
MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
0 0.539668 0.784314 0.043512 ... 0.001499 0.567481 0.211155
1 0.538027 0.392157 0.038224 ... 0.001141 0.565356 0.212151
2 0.466028 1.000000 0.052756 ... 0.001698 0.564293 0.210159
3 0.354699 1.000000 0.035241 ... 0.001493 0.564293 0.209163
4 0.230776 1.000000 0.038534 ... 0.001198 0.564293 0.209163
... ... ... ... ... ... ... ...
20635 0.073130 0.470588 0.029769 ... 0.001503 0.737513 0.324701
20636 0.141853 0.333333 0.037344 ... 0.001956 0.738576 0.312749
20637 0.082764 0.313725 0.030904 ... 0.001314 0.732200 0.311753
20638 0.094295 0.333333 0.031783 ... 0.001152 0.732200 0.301793
20639 0.130253 0.294118 0.031252 ... 0.001549 0.725824 0.309761
[20640 rows x 8 columns]
Đầu ra cho thấy các giá trị được chia tỷ lệ để có giá trị tối thiểu mặc định là 0 và giá trị tối đa là 1.
Bạn cũng có thể chỉ định các giá trị tối thiểu và tối đa khác nhau để chia tỷ lệ. Trong ví dụ sau, giá trị tối thiểu là 0 và giá trị tối đa là 2:
Đầu ra là:
MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
0 1.079337 1.568627 0.087025 ... 0.002999 1.134963 0.422311
1 1.076054 0.784314 0.076448 ... 0.002281 1.130712 0.424303
2 0.932056 2.000000 0.105513 ... 0.003396 1.128587 0.420319
3 0.709397 2.000000 0.070482 ... 0.002987 1.128587 0.418327
4 0.461552 2.000000 0.077068 ... 0.002397 1.128587 0.418327
... ... ... ... ... ... ... ...
20635 0.146260 0.941176 0.059538 ... 0.003007 1.475027 0.649402
20636 0.283706 0.666667 0.074688 ... 0.003912 1.477152 0.625498
20637 0.165529 0.627451 0.061808 ... 0.002629 1.464400 0.623506
20638 0.188591 0.666667 0.063565 ... 0.002303 1.464400 0.603586
20639 0.260507 0.588235 0.062505 ... 0.003098 1.451647 0.619522
[20640 rows x 8 columns]
Đầu ra cho thấy các giá trị được chia tỷ lệ để có giá trị tối thiểu là 0 và giá trị tối đa là 2.
Phần kết luận
Trong bài viết này bạn đã sử dụng hai hàm scikit-learn để chuẩn hóa dữ liệu theo nhiều cách khác nhau theo mẫu (hàng) và theo tính năng (cột). Tiếp tục tìm hiểu về các chủ đề học máy khác .




