Hướng dẫn về Mô-đun csv Python
30/01/2023 01:26
Trong bài viết này, chúng ta sẽ tìm hiểu về các tệp CSV và cách sử dụng Python để làm việc với chúng. Chúng ta sẽ bắt đầu bằng cách tìm hiểu tệp CSV thực sự là gì. csvSau đó, chúng ta sẽ học cách sử dụng mô-đun tích hợp sẵn của Python để đọc và ghi tệp CSV một cách nhanh chóng và hiệu quả
Bạn có thể đã nhìn thấy dữ liệu dạng bảng trước đây: nó chỉ đơn giản là các hàng và cột chứa một số dữ liệu. (Hãy nghĩ về bảng trong một bài báo hoặc bảng tính Excel.) Tệp CSV là một trong những loại bảng phổ biến nhất được các nhà khoa học dữ liệu sử dụng nhưng chúng có thể gây khó khăn nếu bạn không biết chính xác cách chúng hoạt động hoặc cách sử dụng chúng. cùng với Python.
Trong bài viết này, chúng ta sẽ tìm hiểu về các tệp CSV và cách sử dụng Python để làm việc với chúng. Chúng ta sẽ bắt đầu bằng cách tìm hiểu tệp CSV thực sự là gì. csvSau đó, chúng ta sẽ học cách sử dụng mô-đun tích hợp sẵn của Python để đọc và ghi tệp CSV một cách nhanh chóng và hiệu quả.
Cấu trúc của tệp CSV
Tóm lại, tệp CSV là một tệp văn bản thuần túy đại diện cho một bảng. Dữ liệu được lưu trữ dưới dạng hàng và cột. Tên CSV là viết tắt của các giá trị được phân tách bằng dấu phẩy , nghĩa là các cột của bảng được phân tách bằng dấu phẩy. Mặt khác, các hàng được phân định đơn giản bằng các dòng trong tệp. Dòng đầu tiên thường là tiêu đề của bảng, chứa mô tả dữ liệu trong mỗi cột.
Hãy làm việc với một tệp CSV ví dụ có tên people.csv. Đây là giao diện nếu chúng ta mở nó bằng trình soạn thảo văn bản:
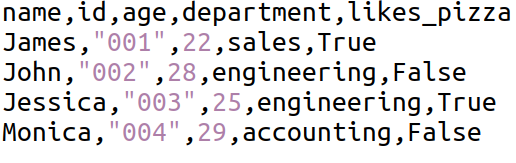
Như bạn có thể thấy, các cột được xác định bằng dấu phẩy. Cột đầu tiên (dưới nhãn tiêu đề namevà ngay trước dấu phẩy đầu tiên trong mỗi dòng) lưu trữ tên của từng người. Sau dấu phẩy đầu tiên là cột id, rồi age, v.v. Các ký hiệu trích dẫn có thể được sử dụng để đóng gói văn bản, như đã thấy trong idcột.
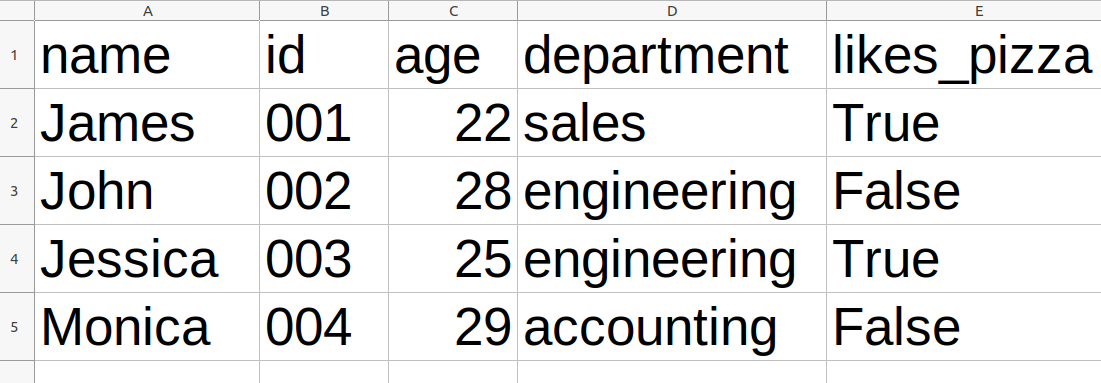
Vì các dấu phẩy không nhất thiết phải thẳng hàng nên sẽ hơi khó để hình dung từng cột trong văn bản thuần túy. Dữ liệu bên trong tệp CSV sẽ dễ hiểu hơn nếu chúng ta mở tệp đó trong bảng tính như Excel, Google Trang tính hoặc LibreOffice Calc:
Sử dụng Python để đọc tệp CSV
Được rồi, chúng tôi có ý tưởng cơ bản về tệp CSV là gì. Nhưng làm thế nào để bạn mở nó bằng Python?
Bạn có thể muốn sử dụng open()chức năng để đọc nội dung của tệp, chia dòng tại mỗi dấu phân cách cột và cuối cùng đưa nó vào cấu trúc dữ liệu như danh sách hoặc từ điển
Các tệp CSV phổ biến đến mức nhóm phát triển Python đã đi trước và tạo csvmô-đun cho chúng tôi. Chúng tôi chỉ cần nhập mô-đun này và chúng tôi sẽ có quyền truy cập vào rất nhiều chức năng liên quan đến tải dữ liệu từ tệp CSV và ghi lại vào chúng.
Chức năng cơ bản nhất để đọc tệp CSV là csv.reader. Chúng ta có thể sử dụng nó bằng cách mở tệp CSV (có open()hàm), sau đó chuyển phần xử lý tệp do open()hàm tạo ra cho hàm csv.reader. Bạn có thể thấy mã trông như thế nào bên dưới. (Chúng tôi cho rằng bạn đang thực thi Python trong cùng thư mục chứa people.csvtệp.)
import csvwith open('people.csv') as csv_file: reader = csv.reader(csv_file) for row in reader: print(row)# output:# ['name', 'id', 'age', 'department', 'likes_pizza']# ['James', '001', '22', 'sales', 'True']# ['John', '002', '28', 'engineering', 'False']# ['Jessica', '003', '25', 'engineering', 'True']# ['Monica', '004', '29', 'accounting', 'False'] |
Như bạn có thể thấy, nó readertự động sắp xếp dữ liệu thành các hàng. Khi chúng tôi lặp lại reader, cuối cùng chúng tôi sẽ lặp lại các hàng trong tệp CSV. Các hàng này được lưu trữ dưới dạng danh sách mà chúng tôi không cần phải tự tạo một danh sách.
Hàm csv.readerchấp nhận nhiều đối số khác nhau để phân tích các tiêu chuẩn định dạng khác nhau trong tệp CSV. Ví dụ: mặc dù có tên "được phân tách bằng dấu phẩy", nhưng một số tệp CSV sử dụng các ký tự khác để phân tách các cột hoặc thậm chí để trích dẫn văn bản. nếu bạn gặp trường hợp như vậy, bạn có thể chỉ định các ký tự này bằng từ khóa delimitervà quotechartừ khóa tương ứng:
import csvwith open('people.csv') as csv_file: reader = csv.reader(csv_file, delimiter=';', quotechar='!') for row in reader: print(row)# output:# ['name,id,age,department,likes_pizza']# ['James,"001",22,sales,True']# ['John,"002",28,engineering,False']# ['Jessica,"003",25,engineering,True']# ['Monica,"004",29,accounting,False'] |
Trong trường hợp này, vì chúng tôi đã sử dụng định dạng delimitervà quotecharđịnh dạng không chính xác trong people.csvtệp của mình, chúng tôi đã kết thúc với các hàng được phân chia kém trong tệp reader. Chúng ta nên sử dụng các giá trị mặc định!
Ở bất kỳ mức độ nào, việc biết cách thay đổi các tham số này sẽ hữu ích nếu bạn gặp một tệp CSV có định dạng khác. Ví dụ: bạn sẽ thường thấy dấu chấm phẩy ( ;) được sử dụng làm dấu phân cách cột trong tệp CSV bắt nguồn từ các quốc gia nơi dấu phẩy ( ,) được sử dụng cho các giá trị thập phân.
Đọc tệp CSV dưới dạng từ điển bằng Python
Các ví dụ của chúng tôi trong phần trước có một vấn đề rõ ràng: hàng tiêu đề xuất hiện cùng với các hàng chứa giá trị! Lý tưởng nhất là vì tiêu đề và giá trị có ý nghĩa khác nhau trong một bảng, nên chúng tôi cũng muốn xử lý chúng theo cách khác.
May mắn cho chúng tôi, có csv.DictReaderđối tượng phục vụ chúng tôi. Nó hoạt động như bình thường csv.readertừ trước (thậm chí bạn có thể chuyển vào cùng các đối số, như delimitervà quotechar), nhưng nó bao gồm các từ điển, thay vì danh sách. Hơn nữa, các khóa của từ điển đến từ tiêu đề của tệp CSV!
Đây là cách nó hoạt động:
import csvwith open('people.csv') as csv_file: reader = csv.DictReader(csv_file) for row in reader: print(row)# output:# {'name': 'James', 'id': '001', 'age': '22', 'department': 'sales', 'likes_pizza': 'True'}# {'name': 'John', 'id': '002', 'age': '28', 'department': 'engineering', 'likes_pizza': 'False'}# {'name': 'Jessica', 'id': '003', 'age': '25', 'department': 'engineering', 'likes_pizza': 'True'}# {'name': 'Monica', 'id': '004', 'age': '29', 'department': 'accounting', 'likes_pizza': 'False'} |
Xem cách các nhãn tiêu đề trở thành chìa khóa cho từ điển của mỗi hàng? Giả csv.DictReaderđịnh rằng hàng đầu tiên là tiêu đề - một giả định rất an toàn - và sử dụng các nhãn của nó để tạo từ điển. Đương nhiên, điều này có nghĩa là hàng tiêu đề không xuất hiện khi lặp qua tệp csv.DictReader.
Lúc đầu, csv.DictReadercó vẻ như không phải là một bước tiến lớn từ csv.reader. Tuy nhiên, việc sử dụng từ điển có nhãn tiêu đề cho phép chúng tôi làm việc với các giá trị rõ ràng hơn nhiều. Mã sau liệt kê tên và tuổi của mọi người – hy vọng bạn sẽ đồng ý với tôi về mức độ rõ ràng và dễ hiểu của mã:
import csvwith open('people.csv') as csv_file: reader = csv.DictReader(csv_file) for row in reader: name = row['name'] age = row['age'] print(name, 'is', age, 'years old.')# output:# James is 22 years old.# John is 28 years old.# Jessica is 25 years old.# Monica is 29 years old. |
Sử dụng Python để ghi tệp CSV
Làm cách nào để ghi dữ liệu vào tệp CSV? Chà, csvmô-đun này bao gồm một csv.writerchức năng cho mục đích đó; nó hoạt động như csv.read. Tuy nhiên, hãy bỏ qua và xem xét họ hàng mạnh mẽ hơn của nó csv.DictWriter. Hãy sử dụng nó để tạo một tệp hoàn toàn mới có tên names.csv:
import csvwith open('names.csv', 'w') as csv_file: header = ['first', 'last'] writer = csv.DictWriter(csv_file, fieldnames=header) writer.writeheader() writer.writerow({'first': 'Jack', 'last': 'Hill'}) writer.writerow({'first': 'James', 'last': 'Mitch'}) |
Có rất nhiều thứ đang diễn ra ở đây, vì vậy hãy thực hiện từng bước một:
- Chúng tôi bắt đầu bằng cách mở tệp ở chế độ ghi (
'w'), thao tác này sẽ tạo tệp CSV hoàn toàn mới trong hệ thống tệp của chúng tôi. - Sau đó, chúng tôi xác định các cột tiêu đề mà tệp CSV của chúng tôi phải có và chuyển nó tới
csv.DictWriterđối tượng bằng cách sử dụngfieldnamesđối số từ khóa. - Sau khi tạo
csv.DictWritervà lưu trữ nó vàowriterbiến, chúng tôi gọiwriter.writeheader(). Thao tác này sẽ tự động ghi tiêu đề vào tệp CSV của chúng tôi. - Sau đó, chúng tôi gọi
writer.writerow(), một vài lần. Với mỗi cuộc gọi, chúng tôi cung cấp một từ điển đại diện cho hàng sẽ được ghi vào tệp CSV. Đương nhiên, các khóa của từ điển phải khớp với tiêu đề mà chúng tôi đã xác định trước đó.




