5 cơ sở dữ liệu Vector hàng đầu bạn nên biết
23/01/2024 01:33
Hướng dẫn toàn diện về cơ sở dữ liệu vector tốt nhất. Làm chủ khả năng lưu trữ dữ liệu chiều cao, giải mã thông tin phi cấu trúc và tận dụng khả năng nhúng vectơ cho các ứng dụng AI.
Trong lĩnh vực Trí tuệ nhân tạo (AI), lượng dữ liệu khổng lồ đòi hỏi phải xử lý và xử lý hiệu quả. Khi chúng tôi đi sâu vào các ứng dụng nâng cao hơn của AI, chẳng hạn như nhận dạng hình ảnh, tìm kiếm bằng giọng nói hoặc công cụ đề xuất, bản chất của dữ liệu trở nên phức tạp hơn. Đây là nơi cơ sở dữ liệu vector phát huy tác dụng. Không giống như cơ sở dữ liệu truyền thống lưu trữ các giá trị vô hướng, cơ sở dữ liệu vectơ được thiết kế độc đáo để xử lý các điểm dữ liệu đa chiều, thường được gọi là vectơ. Các vectơ này, biểu diễn dữ liệu theo nhiều chiều, có thể được coi là các mũi tên chỉ theo một hướng và độ lớn cụ thể trong không gian.
Khi thời đại kỹ thuật số đẩy chúng ta vào kỷ nguyên bị thống trị bởi AI và học máy, cơ sở dữ liệu vectơ đã nổi lên như một công cụ không thể thiếu để lưu trữ, tìm kiếm và phân tích vectơ dữ liệu nhiều chiều. Blog này nhằm mục đích cung cấp sự hiểu biết toàn diện về cơ sở dữ liệu vectơ, tầm quan trọng ngày càng tăng của chúng trong AI và tìm hiểu sâu về cơ sở dữ liệu vectơ tốt nhất hiện có vào năm 2023.
Cơ sở dữ liệu Vector là gì?
Cơ sở dữ liệu vectơ là một loại cơ sở dữ liệu cụ thể lưu thông tin dưới dạng vectơ đa chiều biểu thị các đặc điểm hoặc phẩm chất nhất định.
Số lượng kích thước trong mỗi vectơ có thể rất khác nhau, từ chỉ vài đến vài nghìn, dựa trên độ phức tạp và chi tiết của dữ liệu. Dữ liệu này, có thể bao gồm văn bản, hình ảnh, âm thanh và video, được chuyển đổi thành vectơ bằng nhiều quy trình khác nhau như mô hình học máy, nhúng từ hoặc kỹ thuật trích xuất đặc điểm.
Lợi ích chính của cơ sở dữ liệu vectơ là khả năng định vị và truy xuất dữ liệu nhanh chóng và chính xác theo mức độ gần nhau hoặc giống nhau của vectơ. Điều này cho phép tìm kiếm bắt nguồn từ mức độ phù hợp về ngữ nghĩa hoặc ngữ cảnh thay vì chỉ dựa vào kết quả khớp chính xác hoặc tiêu chí đặt ra như với cơ sở dữ liệu thông thường.
Ví dụ: với cơ sở dữ liệu vectơ, bạn có thể:
- Tìm kiếm các bài hát cộng hưởng với một giai điệu cụ thể dựa trên giai điệu và nhịp điệu.
- Khám phá các bài viết phù hợp với một bài viết cụ thể khác về chủ đề và quan điểm.
- Xác định các tiện ích phản ánh đặc điểm và đánh giá của một thiết bị nhất định.
Cơ sở dữ liệu Vector hoạt động như thế nào?
Cơ sở dữ liệu truyền thống lưu trữ dữ liệu đơn giản như từ và số ở định dạng bảng. Tuy nhiên, cơ sở dữ liệu vectơ hoạt động với dữ liệu phức tạp gọi là vectơ và sử dụng các phương pháp tìm kiếm độc đáo.
Trong khi cơ sở dữ liệu thông thường tìm kiếm dữ liệu trùng khớp chính xác thì cơ sở dữ liệu vectơ tìm kiếm kết quả khớp gần nhất bằng cách sử dụng các thước đo tương tự cụ thể.
Cơ sở dữ liệu vectơ sử dụng các kỹ thuật tìm kiếm đặc biệt được gọi là tìm kiếm Hàng xóm gần nhất gần nhất (ANN), bao gồm các phương pháp như băm và tìm kiếm dựa trên biểu đồ.
Để thực sự hiểu cách cơ sở dữ liệu vectơ hoạt động và nó khác với cơ sở dữ liệu quan hệ truyền thống như SQL như thế nào , trước tiên chúng ta phải hiểu khái niệm nhúng.
Dữ liệu phi cấu trúc, chẳng hạn như văn bản, hình ảnh và âm thanh, thiếu định dạng được xác định trước, đặt ra thách thức cho cơ sở dữ liệu truyền thống. Để tận dụng dữ liệu này trong các ứng dụng trí tuệ nhân tạo và học máy, nó được chuyển đổi thành các biểu diễn số bằng cách sử dụng các phần nhúng.
Việc nhúng giống như đưa cho mỗi mục, cho dù đó là một từ, hình ảnh hay thứ gì khác, một mã duy nhất nắm bắt ý nghĩa hoặc bản chất của nó. Mã này giúp máy tính hiểu và so sánh các mục này một cách hiệu quả và có ý nghĩa hơn. Hãy coi nó như việc biến một cuốn sách phức tạp thành một bản tóm tắt ngắn gọn mà vẫn nắm bắt được những điểm chính.
Quá trình nhúng này thường đạt được bằng cách sử dụng một loại mạng thần kinh đặc biệt được thiết kế cho nhiệm vụ. Ví dụ: nhúng từ chuyển đổi các từ thành vectơ theo cách mà các từ có nghĩa tương tự sẽ gần hơn trong không gian vectơ.
Sự chuyển đổi này cho phép các thuật toán hiểu được mối quan hệ và sự tương đồng giữa các mục.
Về cơ bản, các phần nhúng đóng vai trò là cầu nối, chuyển đổi dữ liệu phi số thành dạng mà các mô hình học máy có thể hoạt động, cho phép chúng phân biệt các mẫu và mối quan hệ trong dữ liệu hiệu quả hơn.
Ví dụ về Cơ sở dữ liệu Vector
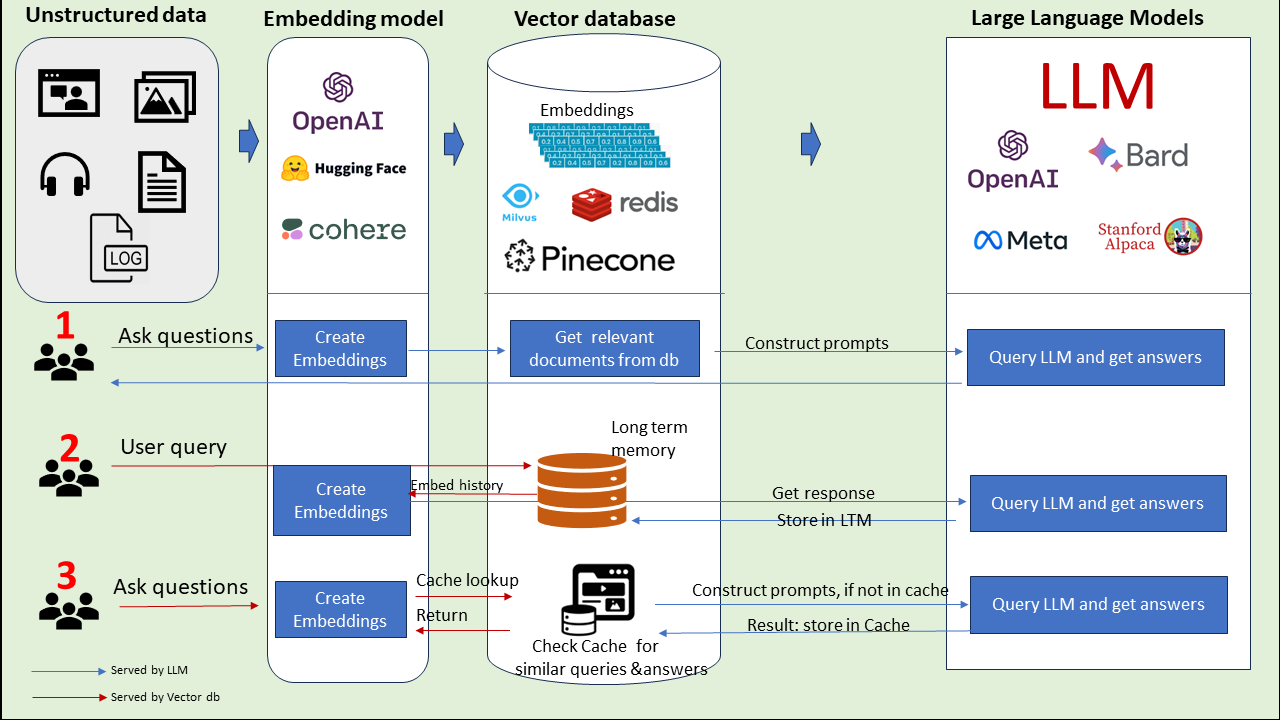
Các trường hợp sử dụng cơ sở dữ liệu vectơ trong các ứng dụng LLM ( Nguồn hình ảnh )
Cơ sở dữ liệu vectơ, với những khả năng độc đáo của chúng, đang tạo ra những ngóc ngách trong vô số ngành nhờ tính hiệu quả của chúng trong việc thực hiện "tìm kiếm tương tự". Sau đây là phần tìm hiểu sâu hơn về các ứng dụng đa dạng của chúng:
1. Nâng cao trải nghiệm bán lẻ
Trong lĩnh vực bán lẻ nhộn nhịp, cơ sở dữ liệu vectơ đang định hình lại cách người tiêu dùng mua sắm. Chúng cho phép tạo ra các hệ thống đề xuất nâng cao, quản lý trải nghiệm mua sắm được cá nhân hóa. Ví dụ: người mua hàng trực tuyến có thể nhận được đề xuất sản phẩm không chỉ dựa trên các giao dịch mua trước đây mà còn bằng cách phân tích những điểm tương đồng về thuộc tính sản phẩm, hành vi của người dùng và sở thích.
2. Phân tích dữ liệu tài chính
Lĩnh vực tài chính tràn ngập các mô hình và xu hướng phức tạp. Cơ sở dữ liệu vectơ vượt trội trong việc phân tích dữ liệu dày đặc này, giúp các nhà phân tích tài chính phát hiện các mô hình quan trọng cho chiến lược đầu tư. Bằng cách nhận ra những điểm tương đồng hoặc sai lệch tinh tế, họ có thể dự đoán diễn biến thị trường và đưa ra các kế hoạch đầu tư sáng suốt hơn.
3. Chăm sóc sức khỏe
Trong lĩnh vực chăm sóc sức khỏe, việc cá nhân hóa là điều tối quan trọng. Bằng cách phân tích trình tự bộ gen, cơ sở dữ liệu vectơ cho phép các phương pháp điều trị y tế phù hợp hơn, đảm bảo rằng các giải pháp y tế phù hợp chặt chẽ hơn với cấu trúc di truyền của từng cá nhân.
4. Tăng cường ứng dụng xử lý ngôn ngữ tự nhiên (NLP)
Thế giới kỹ thuật số đang chứng kiến sự gia tăng đột biến của chatbot và trợ lý ảo. Những thực thể được điều khiển bằng AI này phụ thuộc rất nhiều vào việc hiểu ngôn ngữ của con người. Bằng cách chuyển đổi dữ liệu văn bản rộng lớn thành vectơ, các hệ thống này có thể hiểu và phản hồi chính xác hơn các truy vấn của con người. Ví dụ: các công ty như Talkmap sử dụng khả năng hiểu ngôn ngữ tự nhiên theo thời gian thực, cho phép tương tác giữa khách hàng và đại lý suôn sẻ hơn.
5. Phân tích phương tiện truyền thông
Từ quét y tế đến cảnh quay giám sát, khả năng so sánh và hiểu chính xác hình ảnh là rất quan trọng. Cơ sở dữ liệu vectơ hợp lý hóa việc này bằng cách tập trung vào các tính năng thiết yếu của hình ảnh, lọc nhiễu và biến dạng. Ví dụ: trong quản lý giao thông, hình ảnh từ nguồn cấp dữ liệu video có thể được phân tích nhanh chóng để tối ưu hóa luồng giao thông và tăng cường an toàn công cộng.
6. Phát hiện bất thường
Việc phát hiện những điểm khác biệt cũng cần thiết như việc nhận ra những điểm tương đồng. Đặc biệt trong các lĩnh vực như tài chính và an ninh, việc phát hiện những điểm bất thường có thể đồng nghĩa với việc ngăn chặn gian lận hoặc ngăn chặn hành vi vi phạm an ninh tiềm ẩn. Cơ sở dữ liệu vectơ cung cấp các khả năng nâng cao trong miền này, giúp quá trình phát hiện nhanh hơn và chính xác hơn.
Các tính năng của cơ sở dữ liệu vectơ tốt
Cơ sở dữ liệu vectơ đã nổi lên như những công cụ mạnh mẽ để điều hướng địa hình rộng lớn của dữ liệu phi cấu trúc, như hình ảnh, video và văn bản mà không phụ thuộc nhiều vào nhãn hoặc thẻ do con người tạo ra. Khả năng của họ, khi được tích hợp với các mô hình học máy tiên tiến, có tiềm năng cách mạng hóa nhiều lĩnh vực, từ thương mại điện tử đến dược phẩm. Dưới đây là một số tính năng nổi bật giúp cơ sở dữ liệu vectơ trở thành yếu tố thay đổi cuộc chơi:
1. Khả năng mở rộng và thích ứng
Cơ sở dữ liệu vectơ mạnh mẽ đảm bảo rằng khi dữ liệu phát triển - đạt tới hàng triệu hoặc thậm chí hàng tỷ phần tử - nó có thể dễ dàng mở rộng quy mô trên nhiều nút. Cơ sở dữ liệu vectơ tốt nhất cung cấp khả năng thích ứng, cho phép người dùng điều chỉnh hệ thống dựa trên các biến thể về tốc độ chèn, tốc độ truy vấn và phần cứng cơ bản.
2. Hỗ trợ nhiều người dùng và bảo mật dữ liệu
Cung cấp nhiều người dùng là một kỳ vọng tiêu chuẩn cho cơ sở dữ liệu. Tuy nhiên, chỉ tạo cơ sở dữ liệu vectơ mới cho mỗi người dùng là không hiệu quả. Cơ sở dữ liệu vectơ ưu tiên cách ly dữ liệu, đảm bảo rằng mọi thay đổi được thực hiện đối với một bộ sưu tập dữ liệu vẫn không được nhìn thấy đối với những bộ sưu tập còn lại trừ khi được chủ sở hữu cố ý chia sẻ. Điều này không chỉ hỗ trợ nhiều người thuê mà còn đảm bảo quyền riêng tư và bảo mật dữ liệu.
3. Bộ API toàn diện
Cơ sở dữ liệu chính hãng và hiệu quả cung cấp bộ API và SDK đầy đủ. Điều này đảm bảo rằng hệ thống có thể tương tác với các ứng dụng đa dạng và có thể được quản lý hiệu quả. Cơ sở dữ liệu vectơ hàng đầu, như Pinecone, cung cấp SDK bằng nhiều ngôn ngữ lập trình khác nhau như Python, Node, Go và Java, đảm bảo tính linh hoạt trong phát triển và quản lý.
4. Giao diện thân thiện với người dùng
Giảm đường cong học tập dốc liên quan đến các công nghệ mới, giao diện thân thiện với người dùng trong cơ sở dữ liệu vectơ đóng một vai trò then chốt. Các giao diện này cung cấp cái nhìn tổng quan trực quan, điều hướng dễ dàng và khả năng truy cập vào các tính năng có thể bị che khuất.
5 cơ sở dữ liệu vectơ tốt nhất năm 2023
Danh sách này không theo thứ tự cụ thể - mỗi danh sách hiển thị nhiều phẩm chất được nêu trong phần trên.
1. Sắc tố
Xây dựng ứng dụng LLM bằng ChromaDB ( Nguồn hình ảnh )
Chroma là cơ sở dữ liệu nhúng mã nguồn mở. Chroma giúp việc xây dựng ứng dụng LLM trở nên dễ dàng bằng cách làm cho kiến thức, sự kiện và kỹ năng có thể kết nối được với LLM. Khi chúng tôi khám phá trong hướng dẫn Chroma DB , bạn có thể dễ dàng quản lý tài liệu văn bản, chuyển đổi văn bản thành nội dung nhúng và thực hiện tìm kiếm tương tự.
Các tính năng chính:
- Giàu tính năng: truy vấn, lọc, ước tính mật độ và nhiều tính năng khác
- LangChain (Python và JavScript), LlamaIndex , có hỗ trợ
- API tương tự chạy trong sổ ghi chép Python sẽ mở rộng theo cụm sản xuất
2. Pine Cone
|
NGUỒN MỞ: ❎ |
SAO GITHUB: Không áp dụng ⭐ |

Cơ sở dữ liệu vectơ trái tùng ( Nguồn hình ảnh )
Pinecone là nền tảng cơ sở dữ liệu vectơ được quản lý được xây dựng nhằm mục đích giải quyết những thách thức đặc biệt liên quan đến dữ liệu nhiều chiều. Được trang bị khả năng tìm kiếm và lập chỉ mục tiên tiến, Pinecone trao quyền cho các kỹ sư dữ liệu và nhà khoa học dữ liệu để xây dựng và triển khai các ứng dụng học máy quy mô lớn nhằm xử lý và phân tích dữ liệu nhiều chiều một cách hiệu quả. Các tính năng chính của Pinecone bao gồm:
- Dịch vụ được quản lý hoàn toàn
- Khả năng mở rộng cao
- Nhập dữ liệu theo thời gian thực
- Tìm kiếm có độ trễ thấp
- Tích hợp với LangChain
Để tìm hiểu thêm về Pinecone, hãy xem phần Làm chủ cơ sở dữ liệu vectơ với Hướng dẫn về Pinecone của Moez Ali trên Data Camp.
3. Weaviate
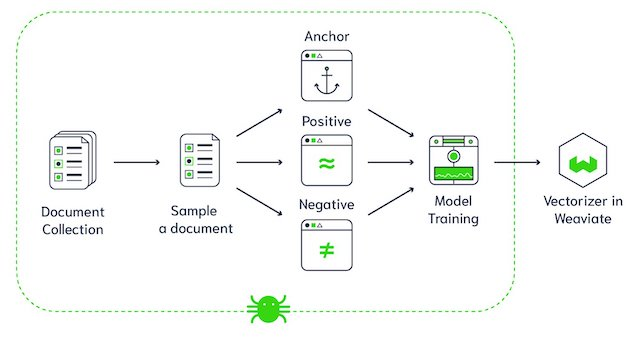
Kiến trúc cơ sở dữ liệu vectơ Weaviate ( Nguồn hình ảnh )
Weaviate là một cơ sở dữ liệu vector mã nguồn mở. Nó cho phép bạn lưu trữ các đối tượng dữ liệu và các phần nhúng vectơ từ các mô hình ML yêu thích của bạn và chia tỷ lệ liền mạch thành hàng tỷ đối tượng dữ liệu. Một số tính năng chính của Weaviate là:
- Tốc độ. Weaviate có thể nhanh chóng tìm kiếm mười hàng xóm gần nhất từ hàng triệu đối tượng chỉ trong vài mili giây.
- Uyển chuyển. Với Weaviate, vector hóa dữ liệu trong quá trình nhập hoặc tải lên dữ liệu của riêng bạn, tận dụng các mô-đun tích hợp với các nền tảng như OpenAI, Cohere, HuggingFace, v.v.
- Sẵn sàng sản xuất. Từ nguyên mẫu đến sản xuất quy mô lớn, Weaviate nhấn mạnh đến khả năng mở rộng, nhân rộng và bảo mật.
- Ngoài tìm kiếm: Ngoài tìm kiếm vectơ nhanh, Weaviate còn đưa ra các đề xuất, tóm tắt và tích hợp khung tìm kiếm thần kinh.
Nếu bạn muốn tìm hiểu thêm về Weaviate, hãy xem Cơ sở dữ liệu vectơ cho khoa học dữ liệu của chúng tôi với hội thảo trực tuyến về Weaviate trong Python trên DataCamp.
4. Faiss
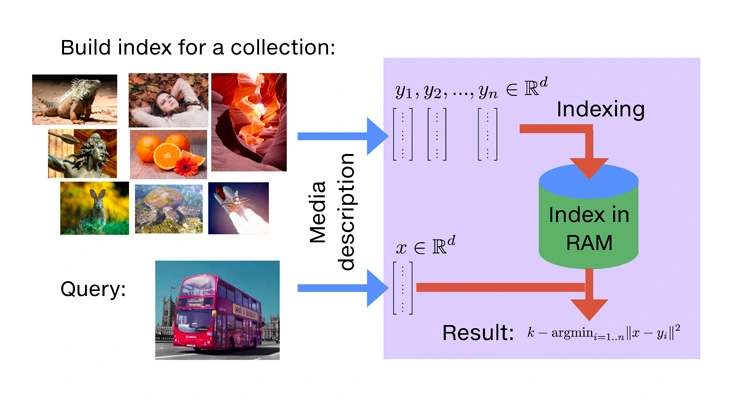
Faiss là một thư viện mã nguồn mở để tìm kiếm vector được tạo bởi Facebook ( Nguồn hình ảnh )
Faiss là một thư viện mã nguồn mở để tìm kiếm nhanh chóng những điểm tương đồng và phân cụm các vectơ dày đặc. Nó chứa các thuật toán có khả năng tìm kiếm trong các tập hợp vectơ có kích thước khác nhau, ngay cả những thuật toán có thể vượt quá dung lượng RAM. Ngoài ra, Faiss còn cung cấp mã phụ trợ để đánh giá và điều chỉnh các thông số.
Mặc dù chủ yếu được mã hóa bằng C++ nhưng nó hỗ trợ đầy đủ tích hợp Python/NumPy. Một số thuật toán chính của nó cũng có sẵn để thực thi GPU. Sự phát triển chính của Faiss được thực hiện bởi nhóm Nghiên cứu AI Cơ bản tại Meta.
5. Qdrant
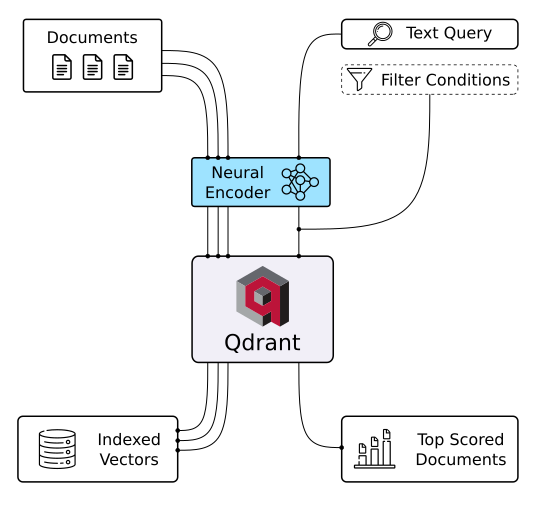
Cơ sở dữ liệu vectơ Qdrant ( Nguồn hình ảnh )
Qdrant là một cơ sở dữ liệu vectơ và một công cụ để tiến hành tìm kiếm độ tương tự của vectơ. Nó hoạt động như một dịch vụ API, cho phép tìm kiếm các vectơ chiều cao gần nhất. Sử dụng Qdrant, bạn có thể chuyển đổi các phần nhúng hoặc bộ mã hóa mạng thần kinh thành các ứng dụng toàn diện cho các tác vụ như đối sánh, tìm kiếm, đưa ra đề xuất và hơn thế nữa. Dưới đây là một số tính năng chính của Qdrant:
- API đa năng . Cung cấp thông số kỹ thuật OpenAPI v3 và ứng dụng khách làm sẵn cho nhiều ngôn ngữ khác nhau.
- Tốc độ và độ chính xác . Sử dụng thuật toán HNSW tùy chỉnh để tìm kiếm nhanh chóng và chính xác.
- Lọc nâng cao . Cho phép lọc kết quả dựa trên tải trọng vectơ liên quan.
- Các kiểu dữ liệu đa dạng . Hỗ trợ khớp chuỗi, phạm vi số, vị trí địa lý, v.v.
- Khả năng mở rộng . Thiết kế dựa trên đám mây với khả năng mở rộng theo chiều ngang.
- Hiệu quả . Rust tích hợp, tối ưu hóa việc sử dụng tài nguyên với lập kế hoạch truy vấn động.
Sự trỗi dậy của AI và tác động của cơ sở dữ liệu Vector
Cơ sở dữ liệu vectơ chuyên lưu trữ các vectơ nhiều chiều, cho phép tìm kiếm độ tương tự nhanh chóng và chính xác. Khi các mô hình AI, đặc biệt là các mô hình trong lĩnh vực xử lý ngôn ngữ tự nhiên và thị giác máy tính, tạo ra và làm việc với các vectơ này, nhu cầu về hệ thống lưu trữ và truy xuất hiệu quả đã trở nên tối quan trọng. Đây là lúc cơ sở dữ liệu vectơ phát huy tác dụng, cung cấp môi trường được tối ưu hóa cao cho các ứng dụng dựa trên AI này.
Một ví dụ điển hình về mối quan hệ giữa cơ sở dữ liệu AI và vectơ được quan sát thấy khi xuất hiện các Mô hình ngôn ngữ lớn (LLM) như GPT-3 .
Những mô hình này được thiết kế để hiểu và tạo ra văn bản giống con người bằng cách xử lý lượng lớn dữ liệu, chuyển đổi chúng thành các vectơ chiều cao. MỘT
các ứng dụng được xây dựng trên GPT-3 và các mô hình tương tự chủ yếu dựa vào cơ sở dữ liệu vectơ để quản lý và truy vấn các vectơ này một cách hiệu quả. Lý do cho sự phụ thuộc này nằm ở khối lượng lớn và độ phức tạp của dữ liệu mà các mô hình này xử lý. Ví dụ: GPT-3, với 175 tỷ tham số, tạo ra một lượng lớn dữ liệu được vectơ hóa mà các cơ sở dữ liệu thông thường khó xử lý một cách hiệu quả.
Source: https://www.datacamp.com/blog/the-top-5-vector-databases#rdl